Lecture 16: Anomaly Detection¶
Video 16-1: Problem Motivation¶
- Like unsupervised problem though some aspects are similar to supervised learning
- Example being discussed of anomaly detection in aircraft engines.
Anomaly detection in aircraft engines¶
Aircraft engine features are :
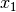 = heat generated
= heat generated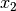 = vibration intensity
= vibration intensity
Dataset = 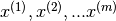
New engine rolls of the assembly line: 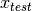
Question: Is the new engine anomalous or should it receive further testing as the two possibilities in the following graph.
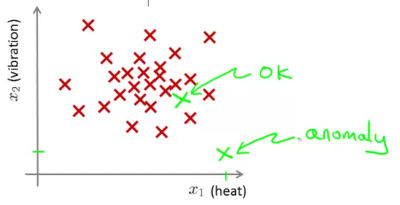
Assumption is that the dataset provided is non-anomalous or normal
We need to build a model to predict the probability of the aircraft being appropriate.
ie. if
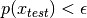 ==> then we flag an anomaly
==> then we flag an anomaly
In the following example, the closer the point is to the inner circle, the higher is the likelihood of it being non-anomalous. On the other hand in the point which is far out (eg. the x near the bottom of the image), the likelihood of the engine being anomalous is high.
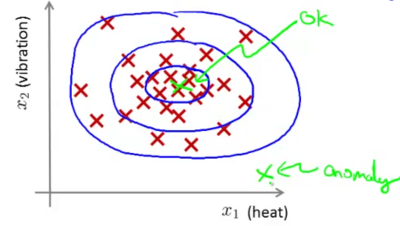
Video 16-2: Anomaly detection example¶
One of the most frequent usages of anomaly detection is that of fraud detection.
 = features of user i’s activities
= features of user i’s activities- Model
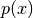 from data
from data - Identify unusual users by checking which may have
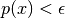
Another use case could be manufacturing (eg. as discussed earlier with aircraft engines).
Anomaly detection can also be used to monitor computers in a data center. eg.
- = features of machine i
- = memory use
- = number of disk accesses / sec
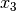 = CPU load
= CPU load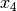 = CPU load / network traffic etc.
= CPU load / network traffic etc.
Identify machines that are likely to fail and flag off for attention.
Video 16-2: Gaussian Distribution¶
Note
This is more of an aside video focusing on Gaussian Distribution per se, rather than anomaly detection.
Say 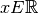 . x is a distributed Gaussian with mean
. x is a distributed Gaussian with mean 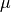 and variance
and variance 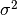 . The distribution is a bell shaped curve centred at .
. The distribution is a bell shaped curve centred at .  (or standard deviation) is indicative of the width of the bell curve.
(or standard deviation) is indicative of the width of the bell curve.
This is expressed as 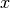 ~
~ 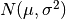
The equation for the probability distribution is :
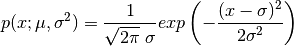

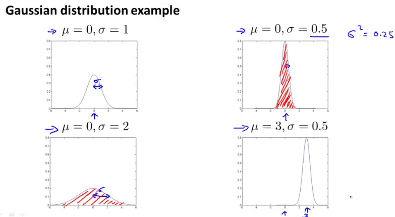
The impact of varying and on the distribution function is shown in the image below.
The equation for computing the mean is :
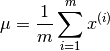
The equation for computing the variance is :
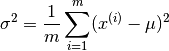
Video 16-3: Anomaly detection algorithm¶
Density estimation¶
Lets say we have a
- Training set :
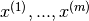 , and
, and - each example is
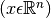 ie. has n features.
ie. has n features.
Assume that each feature is distributed as per gaussian probability distribution. ie. ~ 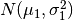 and ~
and ~ 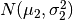 and so on...
and so on...
The computed probability is thus
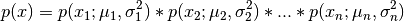
Note
Even if the above formula is that for computing probability for independent variables, in practice it works quite well even if the features are not independent.
The above expression could be summarised as
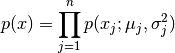
Note
The symbol 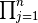 is similar to
is similar to 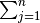 except that it computes the product of all the values in the series rather than adding them up.
except that it computes the product of all the values in the series rather than adding them up.
This computation of the probability is often referred to as Density Estimation.
- Choose features
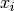 that you think might be indicative of anomalous examples. Especially choose those for whom either unusually high or unusually low values of might be indicative of existence of anomalies.
that you think might be indicative of anomalous examples. Especially choose those for whom either unusually high or unusually low values of might be indicative of existence of anomalies.
- Fit parameters
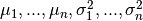 using
using
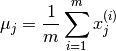
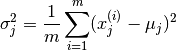
The corresponding vectorised implementations is 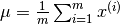 and
and 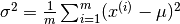 where
where 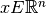
- Given new example , compute
Anomaly detection example¶
Anomaly if
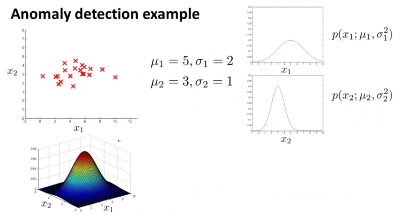
In the above example, and are two different features. The graphs on the right show their gaussian distribution curves, which are different from each other.
At the top left is the plot of the known combinations of and (which of course was used to compute the necessary and values.
The figure at the bottom left shows the effective probability of occurrence of particular combinations of and . Thus any points in this graph where the height of the point on the surface matching the particular point values of and is very low, can be viewed as likely anomalous.
Video 16-4: Developing and evaluating an anomaly detection system¶
- One of the important aspects of being able to develop an anomaly detection system is being able to first have a way of evaluating the anomaly detection system. This can help decide later whether specific feature additions or removals are actually helping or hurting the anomaly detection system.
- The starting point would be some labeled data of anomalous and non-anomalous data (labels being whether the particular case is anomalous or non-anomalous).
- The training set should consist of the non-anomalous subset of the data referredt to above .. these would be
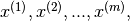 Ideally this data should not contain the anomalous data points. However if a few of them do seep through thats probably not such a big deal.
Ideally this data should not contain the anomalous data points. However if a few of them do seep through thats probably not such a big deal. - On the other hand both the cross validation set
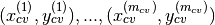 and the test set
and the test set 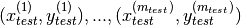 should contain some elements which are known to be anomalous.
should contain some elements which are known to be anomalous.
Example : Aircraft Engines¶
Let us consider a scenario where we have data for 10,000 good/normal engines and 20 flawed/anomalous engines. One may want to consider that the data should be split up as follows :
- Training set: 6000 good engines (unlabeled since all are considered good)
- Cross validation set: 2000 good engines, 10 anomalous
- Test set : 2000 good engines, 10 anomalous
Use the training set to compute 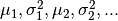 and thus the density estimation as well, ie. fit the model .
and thus the density estimation as well, ie. fit the model .
Now on the cross validation/test example , predict,
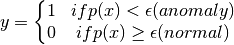
Note: 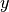 above is a prediction. You can now contrast it with the actual data in your cross validation set. Note that data is extremely skewed ie. #normal points are substantially greater than #anomalous. Thus classification accuracy would not be a good evaluation metric. Instead computing the following might be useful.
above is a prediction. You can now contrast it with the actual data in your cross validation set. Note that data is extremely skewed ie. #normal points are substantially greater than #anomalous. Thus classification accuracy would not be a good evaluation metric. Instead computing the following might be useful.
- % of True/False +ves/-ves, or
- Precision / Recall
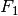 score
score
One could attempt to apply different values of  on the cross validation set, and choose the value that maximises the score. Finally apply the selected value on the test set, and recompute the metrics above.
on the cross validation set, and choose the value that maximises the score. Finally apply the selected value on the test set, and recompute the metrics above.
Video 16-5: Anomaly Detection vs. Supervised Learning¶
If there is labeled data ie. labeled anomalous or normal, why don’t we just use techniques for supervised learning?
- Usually anomaly detection is likely to be useful in scenarios where there is a very very small number of positive (ie. anomalous or = 0) scenarios.
- Anomaly detection might be more useful, where it is hard for an algorithm to learn from positive examples what the anomalies look like (could also cover situations where future anomalies may look nothing like the anomalies we have seen so far).
- Candidate uses for Anomaly detection : Fraud detection, manufacturing defects, monitoring machines in a data center.
- Candidate uses for supervised learning : Email spam classification, Weather prediction, (sunny / rainy etc)., Cancer classification.
Note
If you are a large online retailer and you have data about a large number of users who have been identified to commit fraud, then fraud detection in such a context might shift to a supervised learning approach rather than an anomaly detection one.
Video 16-6: Choosing what features to use¶
Non-gaussian features¶
Would be useful to plot a histogram of various features to get a sense if the features are gaussian. In many situations even if the feature is not showing gaussian distribution, it still might be Ok to consider to go ahead assuming it is so. However sometimes many features show themselves to be substantially non gaussian. In such a situation it might be useful to figure out a transformation to process the feature into a gaussian feature eg. 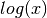 instead of . Other options could be
instead of . Other options could be 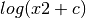 ,
, 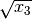 , .. etc.
, .. etc.
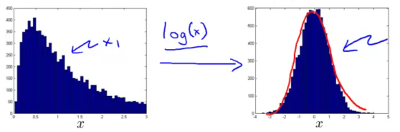
Above: Transformation of a non-gaussian to a gaussian distribution using log(x)
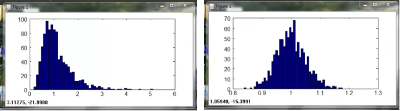
Above: Transformation using :math:`xNew = x ^wedge 0.05`
Error Analysis¶
How does one come up features appropriate for anomaly detection?
- Try to study the features by applying them on the cross validation set.
- You might find situations where say is high for anomalous examples as well. Lets say you find an example where is high for a clearly anomalous situation. Study that particular example to identify perhaps an additional feature that would lead to this particular situation getting flagged as an anomaly.
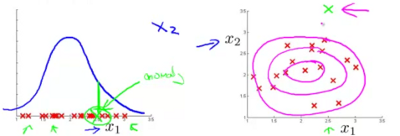
Above: identifying a new feature by looking at anomalies with a high p(x)
- Also prefer to choose features that might take on unusually large or small values in event of an anomaly. Let us imagine memory, disk acceses, cpu load and network traffic are features being looked at for monitoring computers in a data center. Lets imagine that anomalies are more likely to occur when the computer gets stuck in a long while loop, in which case the CPU load is likely to be quite high and the network traffic quite low. This is a candidate case for identification of yet another feature which is the ratio of CPU load to network traffic. (or perhaps even square of cpu load to network traffic). This will help you spot anomalies which are based on unusual combination of features.
Video 16-7: Multivariate Gaussian distribution¶
Sometimes the features have some correlation with each other.
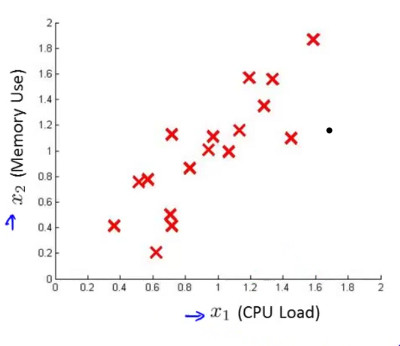
You can see the positive seemingly linear correlation between the two features and . Yet the algorithm above largely assumed these features to be independent. This creates a difficulty as shown in the diagram below.
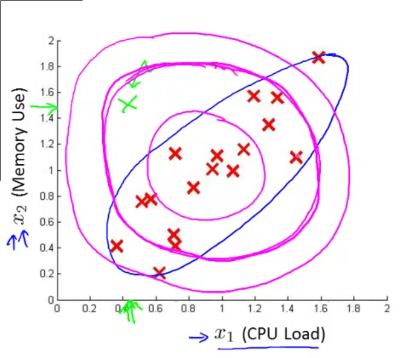
The contours of the probability function computed by independent gaussian variables are similar to the magenta circles drawn above. Yet a casual look can convince us that the contours need to be more along the lines of the contour drawn in the blue line. Thus if you focus on the point marked in green, it should ideally get flagged off as an anomaly, but given the seemingly circular contours, it in this case will not. For this enter - multivariate gaussian distribution.
So for 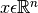 , do not model
, do not model 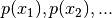 separately assuming them to be independent variables. Model in one go. The parameters to such computations here are
separately assuming them to be independent variables. Model in one go. The parameters to such computations here are 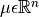 and
and 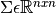 . Note that we have now introduced
. Note that we have now introduced 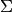 which is the covariance matrix instead of which was just a vector.
which is the covariance matrix instead of which was just a vector.
In such a case the probability function will be computed as follows :
where 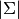 is the determinant of
is the determinant of
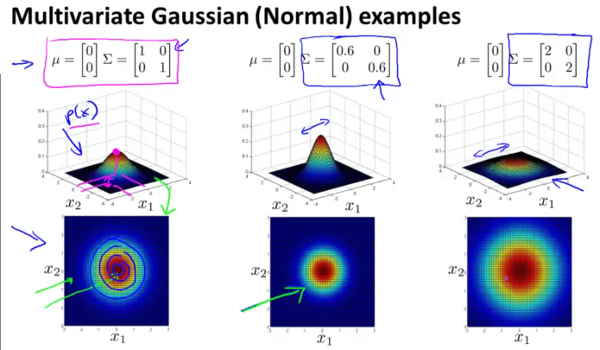
In the figure above it can be seen that by changing the values on the diagonal of the covariance matrix simultaneously, the contours can be made either broader or narrower.
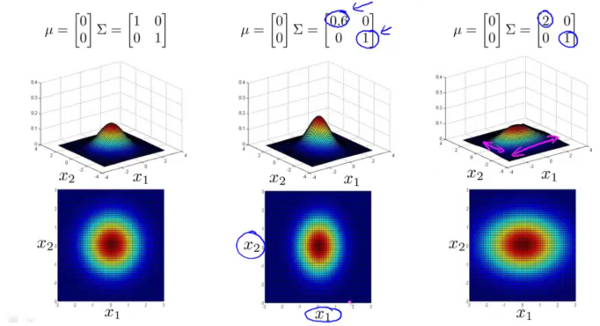
In this figure it can be seen that by independently changing the values on the diagonal of the covariance matrix, the contour profiles can be made to be elliptical along the horizontal and vertical axes.
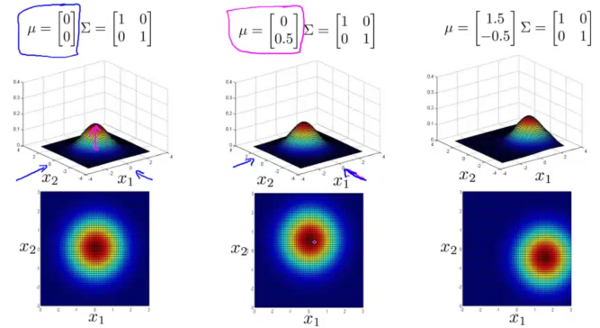
The above figure shows, that by changing the values of , the overall position of the contour profile could be moved.
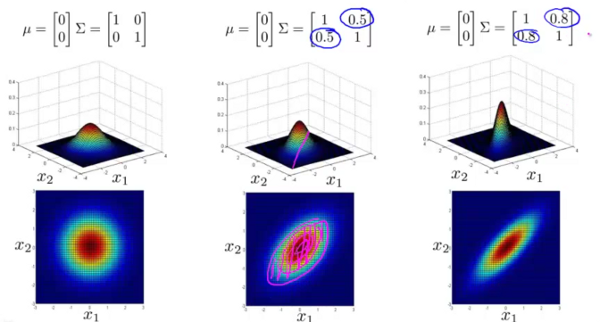
Finally the image above shows that by changing the values on the covariance matrix not on the diagonal, the contour profile changes to an elliptical shape along arbitrary axes. In fact the right most profile is probably closest to the one that we started with. And setting the non-diagonal elements of a correlation matrix to be non-zero is an admission of the fact that these elements are correlated and not independently variable.
So multivariate gaussian distribution should help us model the situation to better fit the actual behaviour of the two features and that we started out with. Thus by using the modified probability function above we can better predict anomalies when the features show some correlation within themselves.
Video 16-8: Anomaly detection using the multivariate gaussian distribution¶
In computing the probability function using a multivariate gaussian distribution the following could be used.
We would need to start by first computing and as follows
Then compute . And flag an anomaly if
Relationship to the original model¶
It turns out that gaussian distribution is simply a special case of multivariate gaussian distribution with the constraint that all the non-diagonal elements of the covariance matrix should be set to zero.
Howeever gaussian distributed still tends to be used more frequently than its multivariate cousin given that the former is computationally cheaper, and can even deal with situations where 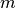 (the training set size) is small or even less than
(the training set size) is small or even less than 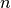 (the number of features). If
(the number of features). If  , multivariate gaussian distribution cannot be used since is non-invertible. It is preferred to generally have
, multivariate gaussian distribution cannot be used since is non-invertible. It is preferred to generally have 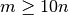 .
.
Quite often (as in the case above of the two correlated features), it might still be helpful to model additional features by creating new features eg. 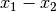 or
or 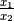 and using gaussian distribution rather then the multivariate gaussian because of the additional computation complexity or if is not substantially larger than .
and using gaussian distribution rather then the multivariate gaussian because of the additional computation complexity or if is not substantially larger than .