Recommender Systems¶
Video 17-1: Problem Formulation¶
- Many websites in silicon valley attempting to build better recommender systems. eg. Amazon recommends books, Netflix recommends movies etc.
- Often these systems are responsible for influencing a substantial portion of their revenues and thus their bottomlines as well.
- Recommender systems receive relatively little attention within academia but a lot from commercial enterprises.
Predicting movie ratings¶
Lets say you allow your users to rate movies using zero (just for the sake of this example) to five stars.

Notations
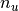 = number of users (
= number of users (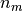 = number of movies
= number of movies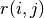 = 1 if user j has rated movie i
= 1 if user j has rated movie i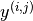 = rating given by user j to movie i
= rating given by user j to movie i
In the above example, you might find Alice & Bob giving high ratings to romatic movies and low ratings to action movies. Carol and Dave rate in exactly the opposite manner.
The problem definition is to look through this data and try to predict what the values of the cells with ? should be. That in turn will form the basis of recommending movies to the users.
Video 17-2: Content-based recommendation¶
Here’s the data.

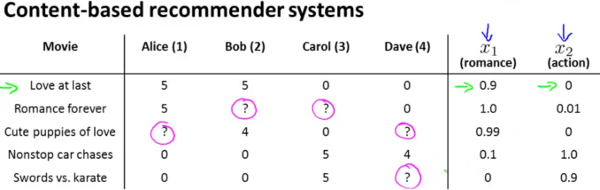
In a content based recommender system, one will have features described for the content of the films which can be used in recommendation. Lets introduce two features 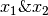 which respectively quantify the extent of romance and action in the movies and provide them appropriate values as follows.
which respectively quantify the extent of romance and action in the movies and provide them appropriate values as follows.
Now one could create a feature vector for the first movie as follows (note an additional feature for the interceptor has been introduced) :
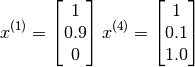
For each user 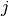 , learn a parameter vector
, learn a parameter vector 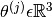 . Predict user as rating movie
. Predict user as rating movie 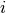 with
with 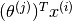 stars.
stars.
Lets say we want to predict what Alice will think of Cute puppies of love. The parameter vector for the movie is as follows
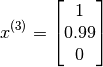
Let us also assume that some as yet unspecified learning algorithm has learned Alice’s preferences as the vector :
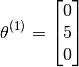
The prediction for Alice’s rating for Cute puppies of love shall be
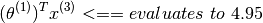
Lets also use yet another variable 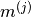 to refer to the number of movies rated by user j. This can be treated as a linear regression problem.
to refer to the number of movies rated by user j. This can be treated as a linear regression problem.
The problem can now be narrowed down to that of minimising over 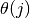 for
for
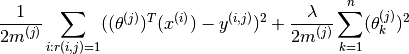
Since is a constant here, and one attempts to minimise the optimisation objective, the equation above can be simplified to
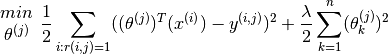
If one wants to simultaneously learn  for all the users, the optimisation objective
for all the users, the optimisation objective  which needs to be minimised, can be further stated as
which needs to be minimised, can be further stated as
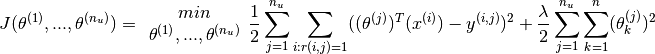
This optimisation function can be then used with gradient descent to incrementally obtain the next value of as follows :
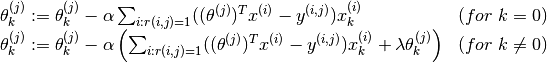
Video 17-3: Collaborative Filtering¶
- This algorithm has an interesting property, feature learning, ie. the algorithm learns what features to use.
- In this case (as shown in the image below) we no longer have explicit rating of the features. Instead each user has told us how much they like romance movies and how much they like action movies (via their values).
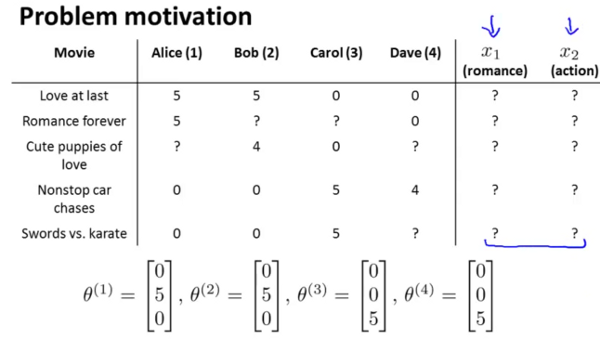
In this case we know the values of , but do not know the values of the features . The question therefore to be answered is what is the value of the vector 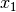 (or similarly
(or similarly 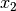 ) which will satisfy the following equations,
) which will satisfy the following equations,
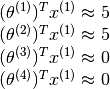
Due to the simplicity of this particular problem one can probably reason quickly that the appropriate value would be
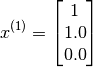
Stating the problem formally, given 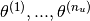 , we are required to learn the feature vector
, we are required to learn the feature vector 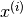 such that,
such that,
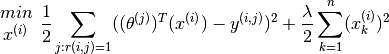
Generalising further, across all features, the problem statement now is, given , we are required to learn the feature vectors 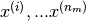 such that,
such that,
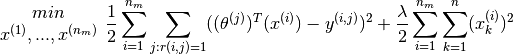
In content based rating, we saw that given a value of feature vectors 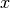 , we could compute , while later we saw that given , we could compute . Thus it is possible that we may apply these methods alternately to converge these values from a starting random value. ie
, we could compute , while later we saw that given , we could compute . Thus it is possible that we may apply these methods alternately to converge these values from a starting random value. ie
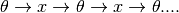
This mechanism of alternatively applying the transformations is called collaborative filtering.
Video 16-4: Collaborative Filtering Algorithm¶
Combining the two optimisation objectives shown earlier, the combined optimisation cost function is
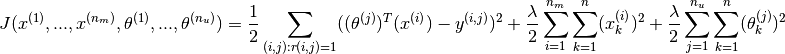
And the optimisation exercise shall then be to minimise the cost function as follows
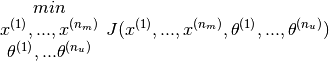
Note that now 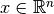 and
and 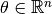 (earlier it was n+1. There is no reason to hard code an extra feature since the algorigthm is going to learn the feature by itself. If one does want to introduce the feature corresponding to the interceptor, one could always start by specifying
(earlier it was n+1. There is no reason to hard code an extra feature since the algorigthm is going to learn the feature by itself. If one does want to introduce the feature corresponding to the interceptor, one could always start by specifying 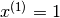
Using the collaborative filter algorithm¶
To apply the algorithm we shall
1. Set 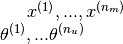 to small random values.
1. Minimise by applying gradient descent (or an advanced optimisation algorithm). Thus
to small random values.
1. Minimise by applying gradient descent (or an advanced optimisation algorithm). Thus
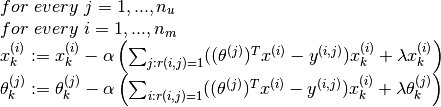
As earlier the two terms that we multiply with 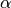 are the partial derivatives of the cost function. Also note, the special cases such as
are the partial derivatives of the cost function. Also note, the special cases such as 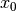 and
and 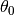 are not present.
are not present.
Once the and matrices are known, we can predict that the rating a user assigns to a movie will be 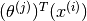
Video 17-5: Vectorisation and Low Rank Matrix Factorisation¶
If we model the composite matrices as follows,
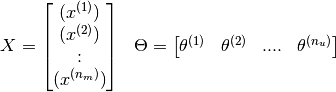
Then the prediction matrix can simply be written as 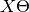 . This resultant matrix is a low rank matrix and hence the name (did not explain what low rank meant).
. This resultant matrix is a low rank matrix and hence the name (did not explain what low rank meant).
After having learned n features, these could theoretically map to romance, action, comedy etc. However in reality, its pretty difficult to derive a human understandable interpretation of what these features are.
The next question we want to focus on is what movies to recommend to a user. In other words, how to find movies j related to movie i?
Turns out if we have the corresponding feature vectors for the movies represented as and 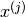 , and if we identify that the distance between these feature vectors
, and if we identify that the distance between these feature vectors 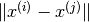 is pretty small, then the two movies are likely to be quite similar.
is pretty small, then the two movies are likely to be quite similar.
So if you want to find 5 most similar movies to movie i, that would be equivalent to finding the 5 movies j with the smallest .
Video 17-6: Implementational detail - Mean normalisation¶
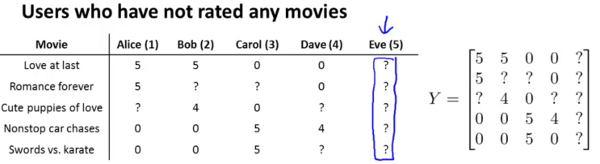
Let us consider a situation where we add a new user Eve to the situation we have been discussing so far. Eve has not rated any movies so far.
Recall the cost function we used was
In this case, since 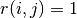 will not be true for any value of
will not be true for any value of 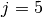 since eve has not rated any movies. So the first term in the function above will have not affect
since eve has not rated any movies. So the first term in the function above will have not affect 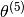 at all. does not appear in the second term. The only place where it will appear is in the third term. as
at all. does not appear in the second term. The only place where it will appear is in the third term. as 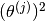 . Minimising this will obviously lead to a to have all its values being zero. Hence the all the predictions for Eve given by
. Minimising this will obviously lead to a to have all its values being zero. Hence the all the predictions for Eve given by 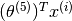 will also have the value zero.
will also have the value zero.
To accomodate for this issue, we will perform mean normalisation as follows. Let us start with a matrix Y of all the ratings as shown in the image above. We compute a vector 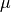 to be the mean of each row in Y. We finally recompute Y by subtracting from itself. This is shown in the image below.
to be the mean of each row in Y. We finally recompute Y by subtracting from itself. This is shown in the image below.

Now we can use this matrix for actually learning 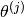 and . But when we have to compute the final prediction, we need to add back
and . But when we have to compute the final prediction, we need to add back 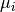 as follows
as follows
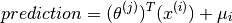
As is obvious, is still set to all zeroes, but the predictions for eve will no longer be zero. They will be those specified by . That seems rather natural, since if we have no idea about a particular new user being introduced, then the prediction we are going to make is that of the average rating.
Note that the technique could also be used to instead account for situations where one introduced a new movie which has no prior ratings and one wanted to predict the ratings for it for each user. But that is rather questionable in the first place, and in any case it is likely to be more important to account for introduction of new users rather than new movies.